Developing Custom Datasets -- Census 2010 SF1

Contents
File>APIGateway enables access to demographic-economic subject matter via API calls. Query, view, analyze, download data to the census block and block group levels using API technology. Use the APIGateway to extract the specific subject matter, for the specific geographic level, for the specific geography that you need -- using a common user interface.
Availability
Levels Viewer,1,2, 3 as option
Using Census 2010 Summary File 1 Census Block Data
See overview in ProximityOne Blog
Install CV XE (11/16/13 version or more recent)
Expand the Washington, DC GIS Project Files http://proximityone.com/dmd/2013_dc_dp.zip to folder c:\cvxe\1.
(for all narrative descriptions to operate correctly use of this folder is required)
With CV XE running, start APIGateway
Use File>APIGateway from main menu bar. The APIGateway form appears as shown below.
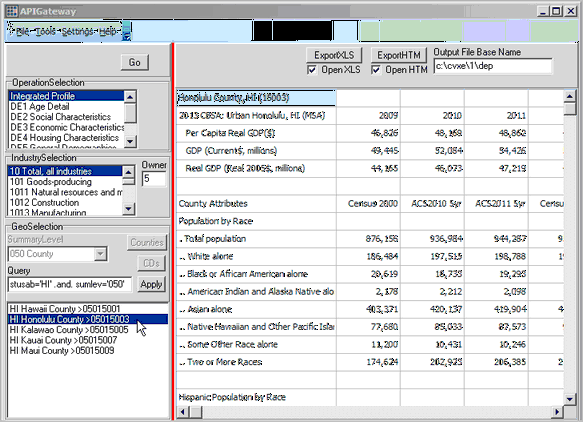
The Batch Extraction operation involves two steps.
1 – Click main menu Settings>Batch Operation and specify settings.
2 – Close the Setting form. Click Tools>Batch Extraction to start processing.
The Batch Operations setting form is shown below.
This view shows available options using the CV XE Viewer version. Grayed out options are available to registered users.
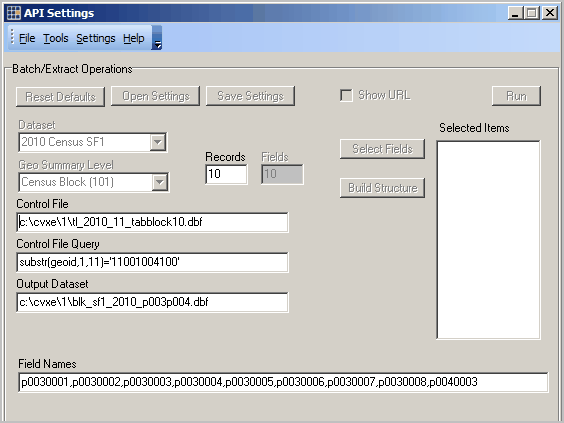
These settings will operate with no modification.
To use these settings, close the form and click Tools>Batch Extraction to start processing.
The output file c:\cvxe\1\blk_sf1_2010_p003p004.dbf is created (Output Dataset) and contains the fields shown in the Field Names edit box.
The output file created will contain ALL records that meet the criteria of the Control File Query (substr(geoid,1,11)=’11001004100′) and processing blocks contained in the Control File (c:\cvxe\1\tl_2013_11_tabblock_dp.dbf).
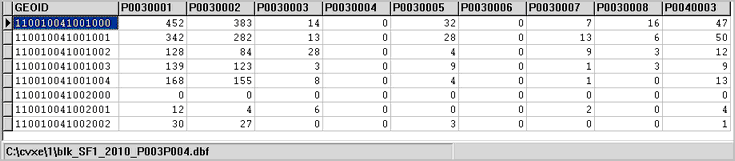
Using the default settings, the output file opened in excel is shown below.
The CV XE Viewer version of the APIGateway will create datasets for any area of the U.S.
The Batch Operation in basic CV XE versions operates only with Census 2010 SF1 block level data.
The full version operates with many types of source data and supports wide ranging geographic levels — including ACS block group level data.
Using the Dataset Generated
There are at least two main ways the output dataset can be used.
1 – the block level data may be aggregated/analyzed in a tabular manner.
2 – the dbase version of the output dataset is structured in a manner that can be immediately joined with a shapefile for mapping and geospatial applications.
More about the Sample Dataset
The first row of the dataset shows selected data for census block 11-001-004100-1000. P0030001 is the fieldname/shorthand for Census 2010 total population. See the list describing these items using the table shells (xls) — see table P3 in the xls file. Field/item.column p0030002 is the White alone population. Field name spelling is nitpicky; one character missed, incorrect or out of place can cause an error. See sequential page 184 (numbered page 6-22 in the matrix section)in the SF1 technical documentation (pdf) to view the exact spelling of the field names and an alternative view of the table structure.
API Settings Form Details and Options
Notes on using the CV XE Viewer version ...
| • | Content of this settings form cannot be saved. |
| • | The Run button is not active; to run current settings in the form use Tools>Run Batch on main API form. |
| • | The reset, open, save settings at the top of form are not active. |
| • | Field names must be manually entered in the Field Names edit box. |
Dataset
Source dataset; default value: 2010 Census SF1
-- no other options are available in the no fee version; see more detail above regarding other options available.
Geo Summary Level
Geographic summary level for data extraction; default value: Census Block (101)
-- no other options are available in the CV XE Viewer version; see more detail above regarding other options available.
Control File
Default value:c:\cvxe\1\tl_2010_11_tabblock10.dbf
Any TIGER/Line census blocks shapefile dbf (tl_2010_??_tabblock10 or more recent) can be used.
For example, the tl_2010_48_tabblock10.dbf file can be used for Texas operations.
This dbf must have the field named GEOID (not GEOID10).
Registered users have access to all ready-to-use state control files (see below).
Control File Query
Default value: substr(geoid,1,11)=’11001004100′
Processes all blocks contained in the Control File (c:\cvxe\1\tl_2010_11_tabblock10.dbf) up to the number specified in the Records edit box.
Optional SQL-like query placed on Control File
| • | If no query is used, this item must be blank. |
| • | An alternative value substr(geoid,1,5)='36065' says to use any geography with state FIPS code 36 (New York) and county FIPS code 065 (Oneida County) |
Records
The Records edit box enables a way to control the number of records extracted.
The purpose of this feature is to enable test runs before running a much larger set of blocks.
The number of records is set to 10 in the default setting.
The number of records may be set to a larger number or ALL (three characters) to process all blocks in the Control File.
Output Dataset
Default value: c:\cvxe\1\blk_sf1_2010_p003p004.dbf
See below for information on creating the Output Dataset structure.
| • | Full path and dBase file name to be created in the API run |
| • | This file referenced here must exist at least in DBF structure for the APIGateway main form Tools>Run Batch to operate. |
The Output Dataset is automatically generated when using the Build Structure operation.
Fields
The maximum number of fields in any one run is limited to 10 fields.
The limit for the commercial version enables extraction of up to 250 fields on one run.
Contact us for details about the commercial version.
Field Names
Default value: p0030001,p0030002,p0030003,p0030004,p0030005,p0030006,p0030007,p0030008,p0040003
| • | Maximum of 50 items per extract. |
| • | This items/field names listed here must be spelled the field names shown in the matrix section of the SF1 technical documentation and spelled verbatim. |
| • | These items/field names must appear, and be defined properly, in the Output Dataset. |
The Field Names list is automatically generated when using the Build Structure operation.
Select Fields/Build Structure
Use this feature to automate the process of using the automated features to build the Output Dataset structure and load the Field Names list.
Click the Select Fields button to start the Field List Manager (FLM). The FLM appears as shown below.
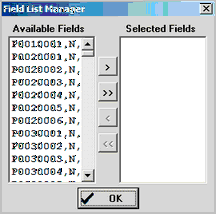
The form is pre-populated with all Census 2010 Summary File 1 items as shown in the left list box.
Click on item(s) is the Available Fields list then click arrows to move the item to the Selected Fields list.
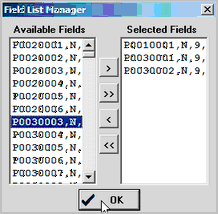
When all desired fields are showing in the Selected Fields listbox, click the Build Structure button.
An OpenFile dialog appears. Enter the name of an output file.
As the Build Structure process operates ...
1. the Output Dataset edit box will be assigned the name of the output file selected.
2. the Field Names list will be populated with the field names showing in the Selected Fields listbox.
The GEOID field is automatically added to the field structure.
With the Control File and Control File Query set as desired, the Run button or APIGateway Tools>Run Batch may now be clicked to start data extraction processing.
Assistance Using these Resources
Join the ProximityOne User Group to obtain resources that can make using the Census 2010 SF1 API data access resources easier.
-- join by checking the User Group option at http://proximityone.com/contact.htm
Using the CV XE GIS Level 1 software, create Output Dataset (see above) structures and view/process dbase files.
User Group members may download Census 2010 census block Control Files (see above).
-- the Census 2010 census block Control Files are available for all states for individual states.
Census 2010 Census Block Control Files Downloads (User Group ID required for remainder of this section)
Terms of use. These files are provided exclusively for with the CV XE GIS software to facilitate APIGateway access to Census 2010 Summary File 1 census block demographics. Redistribution of these state by census block files is not authorized. There is no warranty regarding any aspect of the these files nor any data acquired using the APIGateway. The user is solely responsible for any use.
The state by Census 2010 census block dbase files available via the scroll section below have been derived from the Census Bureau Census 2010 census block shapefiles. The structure and content of the files are the same for each state as shown in the table shown below. The structure of the file is identical to the Census version except that the field GEOID10 has been replaced with GEOID.
| Field Name | Width+Type | Description |
| STATEFP10 | 2 String | 2010 Census state FIPS code |
| COUNTYFP10 | 3 String | 2010 Census county FIPS code |
| TRACTCE10 | 6 String | 2010 Census census tract code |
| BLOCKCE10 | 4 String | 2010 Census tabulation block number |
| GEOID | 15 String | 2010 Block identifier; a concatenation of 2010 Census state FIPS code, county FIPS code, census tract code and tabulation block number. |
| NAME10 | 10 String | 2010 Census tabulation block name; a concatenation of ‘Block’ and the current tabulation block number |
| MTFCC10 | 5 String | MAF/TIGER feature class code (G5040) |
| UR10 | 1 String | 2010 Census urban/rural indicator |
| UACE10 | 5 String | 2010 Census urban area code |
| FUNCSTAT10 | 1 String | 2010 Census functional status |
| ALAND10 | 14 Number | 2010 Census land area |
| AWATER10 | 14 Number | 2010 Census water area |
| INTPTLAT10 | 11 String | 2010 Census latitude of the internal point |
| INTPTLON10 | 12 String | 2010 Census longitude of the internal point |
State by Census 2010 census block dbase files -- expand zip file to c:\cvxe\1\
Alaska
Arizona
Arkansas
California
Colorado
Connecticut
Delaware
DC
Florida
Georgia
Hawaii
Idaho
Illinois
Indiana
Iowa
Kansas
Kentucky
Louisiana
Maine
Maryland
Massachusetts
Michigan
Minnesota
Mississippi
Missouri
Montana
Nebraska
Nevada
New Hampshire
New Jersey
New Mexico
New York
North Carolina
North Dakota
Ohio
Oklahoma
Oregon
Pennsylvania
Rhode Island
South Carolina
South Dakota
Tennessee
Texas
Utah
Vermont
Virginia
Washington
West Virginia
Wisconsin
Wyoming
Creating Output Dataset Structures
These steps show an optional way to create the Output Dataset structure.
Output Dataset structure must correspond to the items being accessed as named in the Field Names section.
The following example illustrates how to create the structure for three items from SF1 table H004.
With CV XE running. use File>Database>dBCreate/Modify
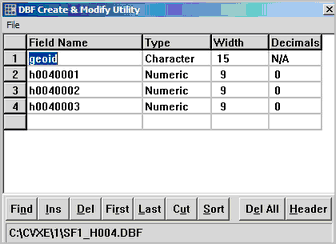
The field names and attributes are entered and the file is saved as c:\cvxe\1\sf1_h004.dbf.
"c:\cvxe\1\sf1_h004.dbf" would be entered in the Output Dataset edit box (no quotes).
Using this example, the Field Names edit box would contain "h0010001,h0040002,h0040003" (no quotes)
Illustrative Application
The API Setting form for the above operation would appear as shown below.
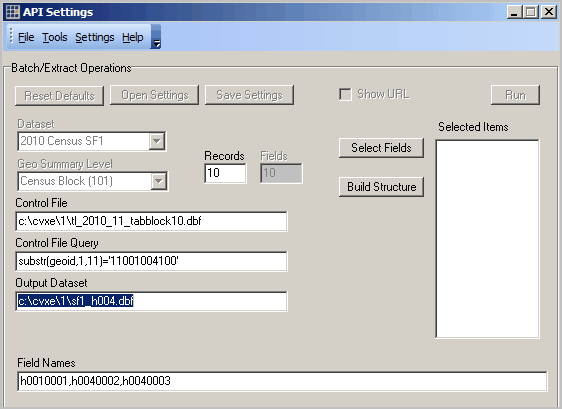
Closing the API Settings form and using Tools>Run Batch creates a 10 record sample file as displayed using Tools>dBrowse:
